Mediative is building a data pipeline on top of Spark so I went to Spark Summit East to see what other people are doing and what’s coming. There were many conference tracks including Enterprise, Developer and Data Science. I mostly attended Data Science talks and below are the highlights. Some of this information also came from NYC Spark Meetup, held on the first evening of the Conference.
Spark 2.0
Some of the main news about Spark 2.0 are
- should be available late April - Early May
- (almost) No API changes for 2.0
- Will unifying datasets and dataframes
DataFrame = Dataset[Row]- Libraries will accept both interchangeably
Tungsten
the under-the-hood improver of memory and CPU efficiency for Spark applications. Project Tungsten was introduced in Spark 1.4. See this blog for more information. Here is what to expect from new releases
- Phase I Spark 2.0
- ~5x faster
- Improve IO by better pruning data to process
- Native memory management (use less java object and their costly initialization)
- Phase II Spark 2.x
- ~10x faster
- Spark will work as a compiler: reading the provided code and create it’s own optimize version.
Spark Streaming
Processing data in real time will be more integrated with batch applications with
- Structured stream
- will extend dataframe/dataset
- more analysis from stream data
- Supports interactive & batch queries (e.g. aggregate data in a stream then serving to JDBC)
(more info on Spark 2.0 here)
Pipelines
The summit comprised lots of of pipeline talks, two examples shown below are particularly interesting for their similarities with our projects at Mediative.
Netflix Distributed Time Travel for Feature Generation
The goal is build a time machine snapshots online services and uses the snapshot data offline to reconstruct the inputs that a model would have seen online to generate features.
First, an appropriate sample of contexts is selected
(samples based on properties such as viewing patterns, devices, time spent on the service, region, etc)
and persisted into S3 (parquet) as represented by the Context Set below.
Interestingly they also store the confidence level for each snapshot service,
the percentage of successful data fetched.
The batch API fetches the associated S3 location of the snapshot data from Cassandra and loads the snapshot data in Spark
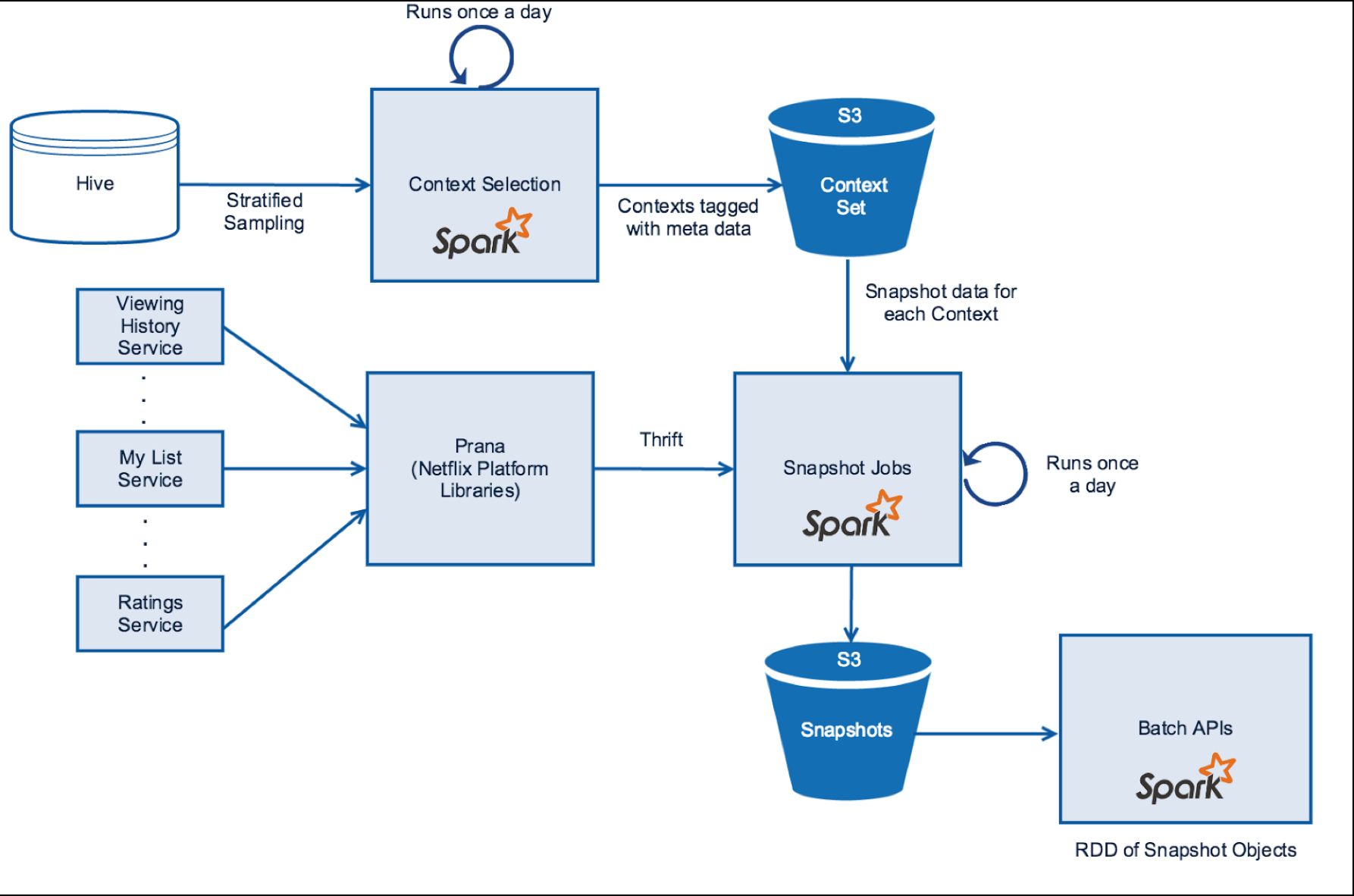
here is an example call to their API returning a RDD
val snapshot = new SnapshotDataManager(sqlContext))
.withTimestams(1445470140000L)
.withContextId(OUTATIME)
.getViewingHistory
(more info here)
Real Time Data Pipelines with Kafka
If you have n connectors, it is very likely that you’ll end up writing n*n connections.
Here is a scary examples

Kafka connect’s two modes
- Source connectors : some system to Kafka
- Synk connectors : From Kafka to some system
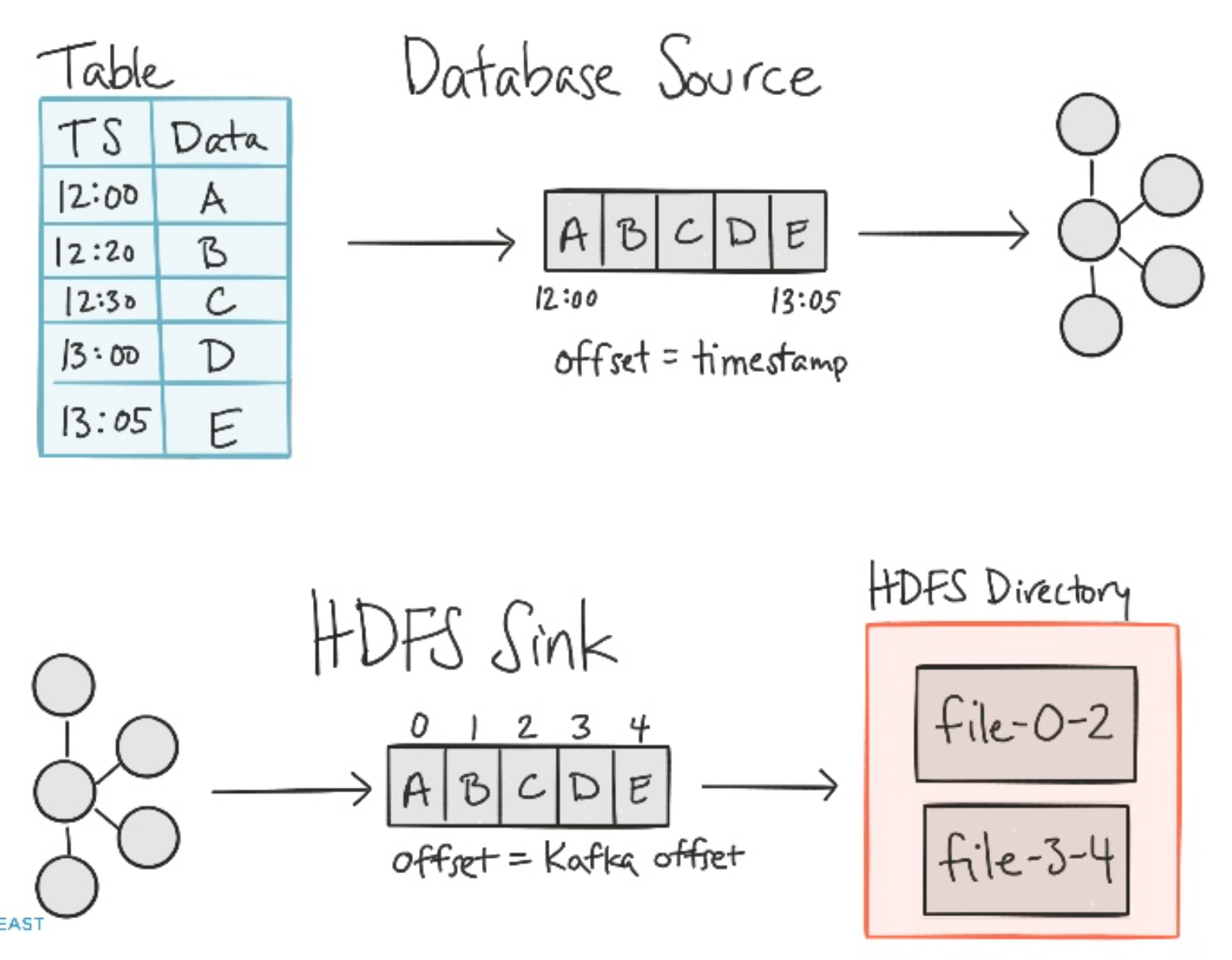
Kafka’s buffer allows to stream to (non-stream) destination like HDFS

It is even possible to copy an entire database (suggested partition: by table)
more information here
Machine Learning
There were many example with MLlib and SparkR and packages like Sparkling water (H2O), an Open Sources with tools like customized DataFrames and Notebook. The incubating SystemML (IBM) translates high-level (R or python) aims to optimized code adapting to underlying input formats and physical data representations.
TensorSpark
A distributed TensorFlow on Spark (Arimo, Inc.) motivated by TensorFlow (at the time) being only released for single-machine. Even with a TensorFlow released, TensorSpark might be more appropriate to join with some spark infrastructure.
The figure below represents how an instance of tensorFlow runs on each machines where the driver is the parameter server: receiving gradients from workers and broadcast the updated model.

more information here
Online bidding
Of particular interest to Mediative, a talk about real time bidding over display ads with machine learning.

Their pipeline could train multiple models in parallel and choose the most effective one. A very nice outcome was the most effective model varies from campaign to campaign as shown below.

Visualization
Visualisation still mostly rely on (non-scalable) libraries although significant progress was shown with integration of ggplot2 with SparkR where 47% of API implemented (as shown here). There is also the incubatin Zoomdate which shows nice promises. Meanwhile, better to filter your data and use a non-distributed library.
Others
A quick mention of interesting subjects
Magellan-Spark Geospatial analytics
- Cartesian join : joining polygone and points
- supported formats includes GeoJSON, ESRI, OSM-XML
Beyond Collect and Parallelize for Tests
- Addressing problems of testing at scale
- Comparing RDD, DataFrames, DataSets
- Getting test (big) data
Spark community edition (beta)
Finally, Databricks announced a free edition of their very nice service, this includes access to 6GB clusters.
beta edition available in the coming weeks
Includes learning utilities
See demo